多图预警👀
字 数
1740
预计阅读时间
8m 24s
京东商品信息爬取
根据b站视频京东耳机数据爬虫改造的——口红数据爬取~
尝试提取:
- 价格
- 名称
- 评论数
- 配送信息
- 优惠信息
获取页面内容
import requests
from bs4 import BeautifulSoup
# 1.获取页面源代码
url = "https://search.jd.com/Search?keyword=%E5%8F%A3%E7%BA%A2&qrst=1&wq=%E5%8F%A3%E7%BA%A2&stock=1&psort=3&click=0"
r = requests.get(url)
print(r) # 打印出了状态码
print(r.text) # 要你进入登录页面
<Response [200]>
<script>window.location.href='https://passport.jd.com/uc/login'</script>
状态码:
200(说明ok)/404/403/301/302
window.location
要你进入登录界面,如何解决:
- 模拟登陆
- 浏览器可以访问,说明被反爬虫了,模拟浏览器
user-agent
如何做?user-agent(实例1里做过了)
url = "https://search.jd.com/Search?keyword=%E5%8F%A3%E7%BA%A2&qrst=1&wq=%E5%8F%A3%E7%BA%A2&stock=1&psort=3&click=0"
header = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
r = requests.get(url, headers = header)
soup = BeautifulSoup(r.text,'html.parser')
len(soup)
# print(soup)
12
xpath获取内容
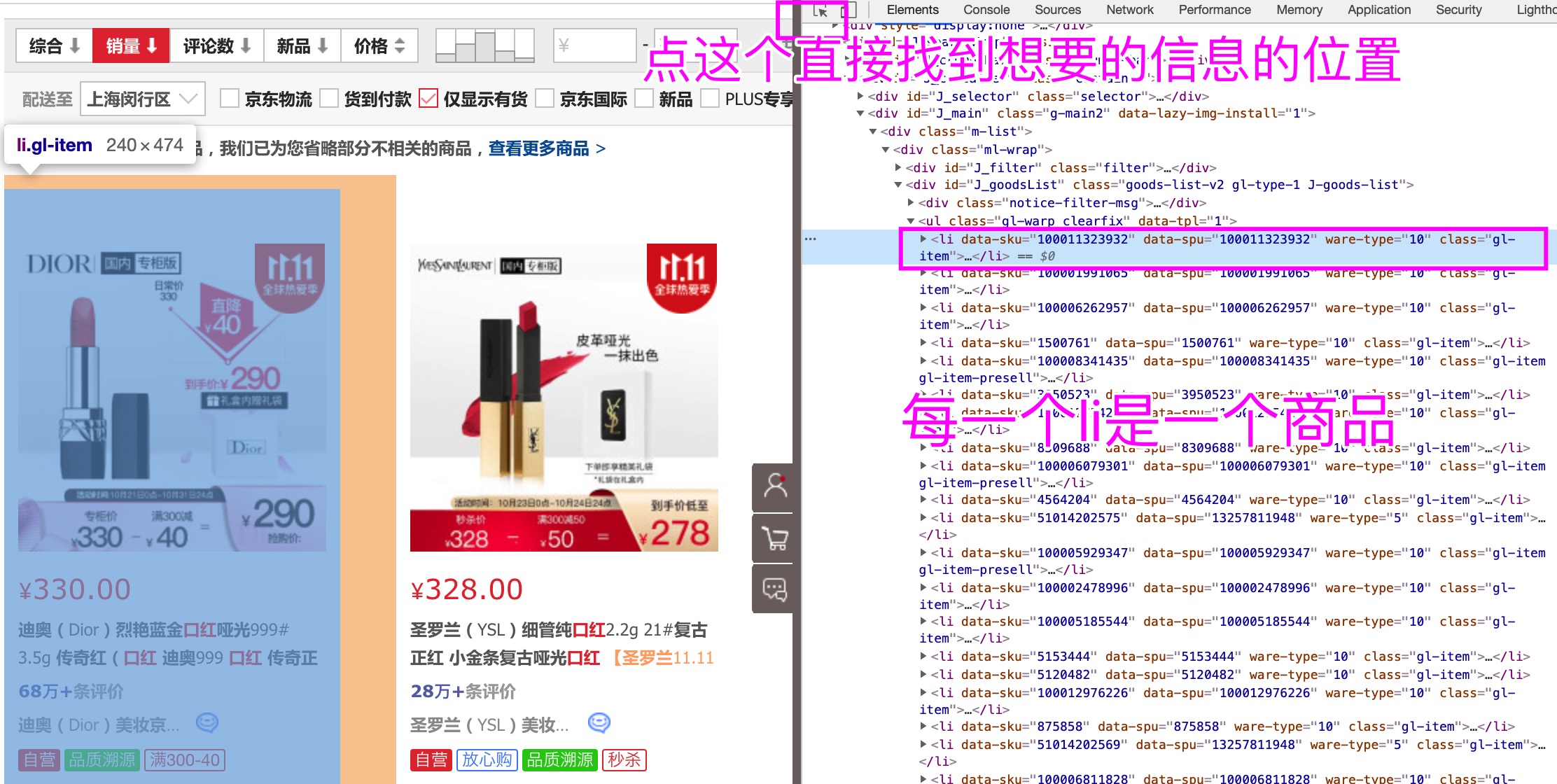
第一步、获取ul标签下所有的li
什么好获取——id是唯一的
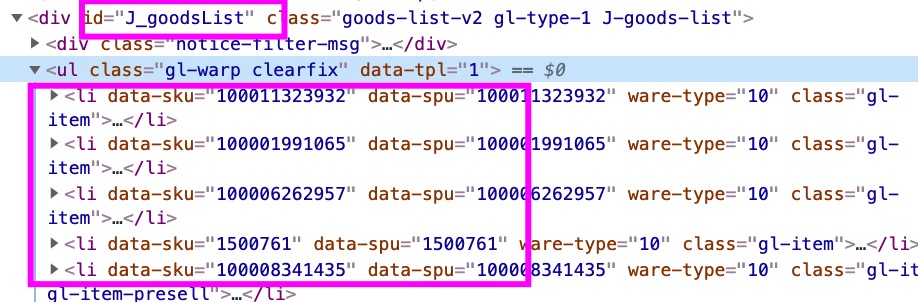
- ul不好获取,但是上面的div有唯一属性id = "J_goodsList",
- 可以先找到这个 div,在下面找到 ul 和下面的所有 li
from lxml import etree # xpath
# 1.获取所有li
html = etree.HTML(r.text) # 处理为xpath可以操作的格式
li_list = html.xpath("//div[@id='J_goodsList']/ul/li") # 得到所有li
第二步、获取li下面的各项信息
-
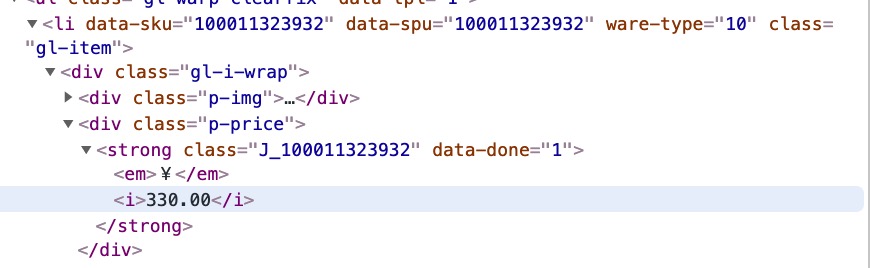
价格和名字直接根据结构写xpath找到
-
评论呢?
# 2.获取各项信息
li0 = li_list[0] # 取第一个商品
# 价格
price = li0.xpath(".//div[@class='p-price']/strong/i/text()")
# 名字
titles_ = li0.xpath(".//div[@class='p-name p-name-type-2']/a/em/text()")
titles = ["".join(titles_)]
print(price, titles)
['330.00'] ['迪奥(Dior)烈艳蓝金哑光999# 3.5g 传奇红( 迪奥999 传奇正红 精美礼盒/礼袋随机)']
第三步、动态加载问题解决评论数获取
评论数量是变化的,所以是动态加载出来的,如果找到呢?
- 参考操作 python 京东页面提取

得到:
https://club.jd.com/comment/productCommentSummaries.action?referenceIds=100011323932,100001991065,100006262957,1500761,3950523,100012754240,100008341435,100006079301,8309688,4564204,51014202575,100005929347,100005185544,100002478996,5153444,5120482,100012976226,875858,51014202569,100013500996,8683285,63512766378,100006965554,5051885,100013038018,100008029287,5469830,100014924764,100007090981,100006979685&callback=jQuery9688568&_=1603461054566
- 如果把后面的"&callback=jQuery9688568&_=1603461054566"都去掉,会变成这样(可以进行request)
https://club.jd.com/comment/productCommentSummaries.action?referenceIds=100011323932,100001991065,100006262957,1500761,3950523,100012754240,100008341435,100006079301,8309688,4564204,51014202575,100005929347,100005185544,100002478996,5153444,5120482,100012976226,875858,51014202569,100013500996,8683285,63512766378,100006965554,5051885,100013038018,100008029287,5469830,100014924764,100007090981,100006979685
-
接着就可以对这个新的url进行内容获取
-
发现评论对应着商品id(SkuId),它其实是每一个li标签的一个属性data-sku的值
-
发现评论的网址格式为https://club.jd.com/comment/productCommentSummaries.action?referenceIds=商品id1,商品id2,.... 因此可以根据id生成url,从而获取评论数
stu = li0.xpath("@data-sku")[0]
# 生成0号商品的评论数网址
url_comment = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds={}".format(str(stu))
print(url_comment)
comment = requests.get(url_comment, headers = header).json()
comments = comment['CommentsCount'][0]
print(comment)
https://club.jd.com/comment/productCommentSummaries.action?referenceIds=100011323932
{'CommentsCount': [{'SkuId': 100011323932, 'ProductId': 100011323932, 'ShowCount': 10450, 'ShowCountStr': '1万+', 'CommentCountStr': '68万+', 'CommentCount': 684913, 'AverageScore': 5, 'DefaultGoodCountStr': '55万+', 'DefaultGoodCount': 555723, 'GoodCountStr': '13万+', 'GoodCount': 131212, 'AfterCount': 1776, 'OneYear': 0, 'AfterCountStr': '1700+', 'VideoCount': 423, 'VideoCountStr': '400+', 'GoodRate': 0.96, 'GoodRateShow': 96, 'GoodRateStyle': 144, 'GeneralCountStr': '1800+', 'GeneralCount': 1840, 'GeneralRate': 0.013, 'GeneralRateShow': 1, 'GeneralRateStyle': 2, 'PoorCountStr': '2900+', 'PoorCount': 2979, 'SensitiveBook': 0, 'PoorRate': 0.027, 'PoorRateShow': 3, 'PoorRateStyle': 4}]}
整理成为循环,批量获取数据,并整理
import numpy as np
# 1.定义函数——输入: li,输出: 商品stuid、评论相关变量
def comment_info(li):
# 1. 获取商品id
stu = li.xpath("@data-sku")[0]
# 2.生成商品的评论数网址
url_comment = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds={}".format(str(stu))
comment = requests.get(url_comment, headers = header).json()
comments = comment['CommentsCount'][0]
# 3.获取评论相关变量
CommentCount = comments['CommentCount'] # 评价总数
DefaultGoodCount = comments['DefaultGoodCount'] # 默认好评数
GoodCount = comments['GoodCount'] # 好评数
GeneralCount = comments['GeneralCount'] # 中评数
PoorCount = comments['PoorCount'] # 差评数
AfterCount = comments['AfterCount'] # 追评
VideoCount = comments['VideoCount'] # 视频评价数
GoodRate = comments['GoodRate'] # 好评率
return stu,CommentCount,DefaultGoodCount,GoodCount,GeneralCount,PoorCount,AfterCount,VideoCount,GoodRate
# 2.定义函数——输入li,输出商品名称和价格
def nameprice_info(li):
# 获取商品价格
price = np.float(li.xpath(".//div[@class='p-price']/strong/i/text()")[0])
# 获取商品名称
titles_ = li.xpath(".//div[@class='p-name p-name-type-2']/a/em/text()")
titles = ["".join(titles_)][0].replace(" ","").replace("\t\n","")
labels = li.xpath(".//div/i/text()")
return titles, price,labels
# 测试
li0 = li_list[0]
titles, price, labels = nameprice_info(li0)
stuid,CommentCount,DefaultGoodCount,GoodCount,GeneralCount,PoorCount,AfterCount,VideoCount,GoodRate = comment_info(li0)
titles, stuid, price, labels, CommentCount,DefaultGoodCount,GoodCount,GeneralCount,PoorCount,AfterCount,VideoCount,GoodRate
('迪奥(Dior)烈艳蓝金哑光999# 3.5g 传奇红( 迪奥999传奇正红 精美礼盒/礼袋随机)',
'100011323932',
330.0,
['自营', '品质溯源', '满300-40'],
684915,
555719,
131218,
1840,
2979,
1776,
423,
0.96)
# all变量
lipsticks = []
for i in range(len(li_list)):
li = li_list[i]
tmp = [None]*12
tmp[1], tmp[2], tmp[3] = nameprice_info(li)
tmp[0], tmp[4], tmp[5], tmp[6], tmp[7], tmp[8], tmp[9], tmp[10], tmp[11]= comment_info(li)
lipsticks.append(tmp)
import pandas as pd
lipsticks_df = pd.DataFrame(lipsticks, columns= ["stuid","titles","price","labels","CommentCount评价总数",\
"DefaultGoodCount默认好评数","GoodCount好评数","GeneralCount中评数","PoorCount差评数","AfterCount追评数","VideoCount视频评论数","GoodRate好评率"])
print("京东口红商品信息爬取成功:")
lipsticks_df.head()
京东口红商品信息爬取成功:
| stuid | titles | price | labels | CommentCount评价总数 | DefaultGoodCount默认好评数 | GoodCount好评数 | GeneralCount中评数 | PoorCount差评数 | AfterCount追评数 | VideoCount视频评论数 | GoodRate好评率 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100011323932 | 迪奥(Dior)烈艳蓝金哑光999# 3.5g 传奇红( 迪奥999传奇正红 精美礼盒/礼袋随机) | 330.0 | [自营, 品质溯源, 满300-40] | 684915 | 555717 | 131220 | 1840 | 2979 | 1776 | 423 | 0.96 |
| 1 | 100001991065 | 圣罗兰(YSL)细管纯2.2g 21#复古正红 小金条复古哑光 | 328.0 | [自营, 放心购, 品质溯源, 秒杀, 满300-50] | 282034 | 231553 | 49332 | 661 | 938 | 702 | 204 | 0.96 |
| 2 | 100006262957 | 迪奥(Dior)烈艳蓝金唇膏滋润999# 3.5g 经典正红色 ( 迪奥 迪奥999 赠礼盒... | 330.0 | [自营, 品质溯源, 满300-40] | 684915 | 555717 | 131220 | 1840 | 2979 | 1776 | 423 | 0.96 |
| 3 | 1500761 | 纪梵希(Givenchy)小羊皮306#3.4g 礼盒装(又名:高定香榭唇膏N306 斩男番... | 345.0 | [自营, 品质溯源] | 393924 | 311890 | 111614 | 1154 | 1771 | 1179 | 443 | 0.97 |
| 4 | 3950523 | 迪奥(Dior)烈艳蓝金999哑光唇膏3.5g(迪奥 正红色 传奇红唇 礼物送女友) | 212.0 | [自营, 品质溯源, 秒杀, 券300-40, 满99-20] | 452385 | 362651 | 93423 | 1485 | 2193 | 1340 | 337 | 0.96 |