今天的男主角是一个神奇的R包——MLR。最近在肝数据挖掘课大作业,顺便拿R跑了跑 machine learning, 之前基本都是用 ggplot2,总觉得R涉及机器学习部分有点零乱(因为要装各种包需要的数据结构也不太一样,总之相比 sklearn 显得挺麻烦的?)这几天突然看到了这个MLR!!用完感觉神仙救了我一命,快速就把作业搞定啦!开心
那今天就拿大作业为例,讲讲我们今天的男主角神仙R包叭!作业所有的 code & data 都放在 github 上面啦,随时更新,欢迎各位老铁关注、点星嘿嘿。
最后还想分享下有关我们作业的有趣发现~
mlr包的流程
以一个基本的逻辑回归来看看:
# 1.加载我们今天的男主——mlr包
library(mlr)
# 2.定义一个分类问题,target就是因变量
classif.task = makeClassifTask(data = data, target = "y")
n = getTaskSize(classif.task)
random_index = sample(x = 1:n, size = n * 0.8, replace = F)
train.set = random_index # 划分训练集合
test.set = (1:n)[-random_index]
# 3.选择学习器(面向对象的味道和 sklearn 灰常像
logistic_learner = makeLearner("classif.logreg", predict.type = "prob", fix.factors.prediction = TRUE)
# 4. 训练模型
lr_model = train(logistic_learner, classif.task, subset = train.set)
# 5. 预测
lr.pred = predict(lr_model, task = classif.task, subset = test.set)
复制粘贴!完事了!交作业!!!高老师一拳一个糊弄学大师
算了算了,具体来说有四个步骤:
第一步 定义我们的研究问题
这里是一个二分类问题,使用makeClassifTask(),其他的类型的问题见下面。要给出一个数据表(data.frame),target就是我们的响应变量(Y),其他列默认为解释变量(X1-Xn)。注意!变量不可以是 strings 必须转化为 factor 或者 numeric。
- RegrTask() for regression problems,
- ClassifTask() for binary and multi-class classification problems with class-dependent costs can be handled as well),
- SurvTask() for survival analysis,
- ClusterTask() for cluster analysis,
- MultilabelTask() for multilabel classification problems,
- CostSensTask() for general cost sensitive classification (with example-specific costs).
第二步 选择模型
呜呜呜这次作业所有模型都要做(不过这正体现了男主角的优越性!),用 makeLearner 来选择学习器。所有学习器的列表在这里可以看到。
你会发现它汇总了了88种Classification,59种Regression,12种Survival analysis,10种Cluster analysis,还有 Multilabel classification等等🤙🤙🤙所有的方法还会标注出能否处理factor、NA等特殊情况,简直是太!贴!心!了!
第三步 训练和预测
这部分就没什么好说的了,直接 train + predict,有几个常用注意点:
- subset 参数使用训练集 or 测试集
- names函数可以看到 train/ predict 里面有什么信息,然后直接用$进行访问,就和我们一般用R包跑出来的是一样的哈。
- weights 参数可以对类失衡的问题进行重采样
- 预测结果包含真实值(truth)和预测值(response)。如果想要输出概率值(比如画个ROC曲线之类的),需要在 makeLearner那里加上 predict.type = "prob",预测结果就会增加概率值~
交叉验证搜索最优参数
如果你觉得掉包也不麻烦,一两行代码的事,那 mlr 最棒的点就是搜索最优参数了。
这里以KNN搜索最佳K值为例:
- 首先用 getLearnerParamSet 看看所有超参数及其取值范围,然后结合理论知识和经验(实话说,结合百度各种博客的说法哈哈哈),
- 用 makeParamSet 选几个参数和一些常见的调参范围。
- 设置 makeResampleDesc 进行交叉验证
- 直接 tuneParams 开始交叉验证搜索参数就完事了
原本挨个掉包写循环的我直呼好家伙...
getLearnerParamSet(makeLearner("classif.kknn")) # 获取所有超参数
rdesc = makeResampleDesc("CV", iters = 5L) # 5折交叉验证
discrete_ps = makeParamSet( # 参数空间
makeDiscreteParam("k", values = c(1, 3, 5, 10, 20, 30, 50, 80, 100))
)
ctrl = makeTuneControlGrid()
res = tuneParams("classif.kknn", task = classif.task,
resampling = rdesc, par.set = discrete_ps, control = ctrl)
res # 搜索结果:
## Tune result:
## Op. pars: k=3
## mmce.test.mean=0.3585818
得到的最优参数K = 3(这时候交叉验证 test 平均误差最低),利用 setHyperPars 用得到的最优参数建模,再 train + prediction 就完事了!
# 获得最优参数
knn_best = setHyperPars(makeLearner("classif.kknn", predict.type = "prob"), k = res$x$k)
# 用最优参数建模
knn_model_best = train(knn_best, classif.task, subset = train.set)
knn.pred = predict(knn_model_best, task = classif.task, subset = test.set)
在输出预测准确率、 ROC 和 AUC,作业不就是分分钟完事啦?夸我谢谢。
library(pROC) # 画ROC曲线
library(ROCR) # 算AUC值
# 输入我们的模型预测结果
plotROC <- function(input){ # roc_curve
modelroc <- roc(input$truth, input$prob.TRUE)
plot(modelroc, print.auc=TRUE,auc.polygon=TRUE,
auc.polygon.col="#f6f6f6", print.thres=TRUE,main = "ROC curve")
}
Accuracy <- function(input){ # matrix & accuracy
res = table(input[, c("truth", "response")]) # rf预测结果
print(res)
return(sum(diag(res)) / sum(res))
}
补充
关于我们的作业,一些有趣的发现
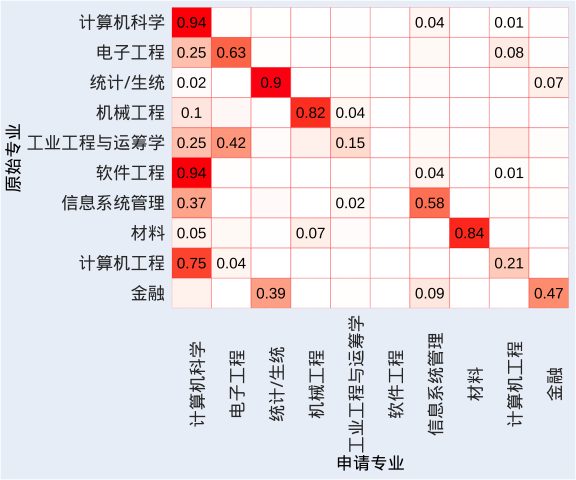
1. CS 有多卷?
左边为原始专业(来源),下方为申请专业(去向)。肉眼可见第一列飘红,果然是全民CS的时代,机械专业同学1 /4 都飘去了CS,果然卷还是CS卷。而统计专业的话,本科统计一般还是会继续申统计,当然还有一批本科金融的同学和你竞争申请,也要越来越卷的节奏。
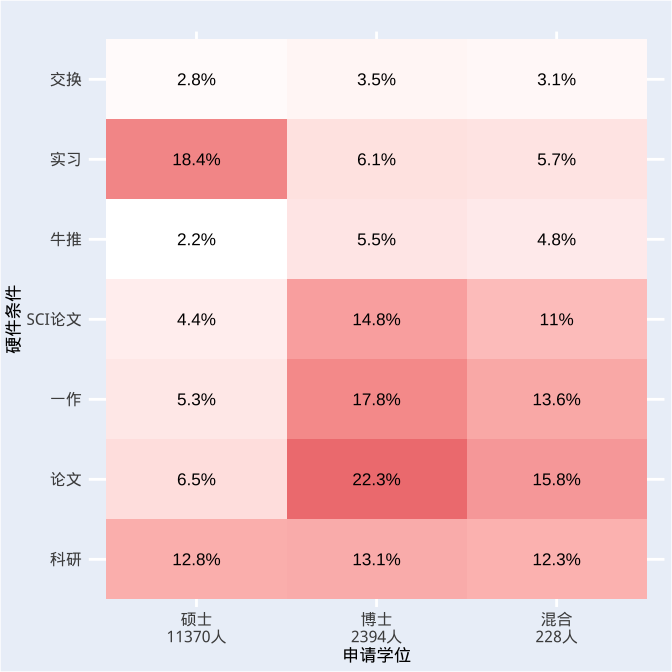
2.PhD难在哪儿?
博士一列“论文、SCI、一作”都飘红,申请博士也太太太卷了叭!至今没有论文的小菜鸡当场抹眼泪...而申请硕士的话专注实习就好了。
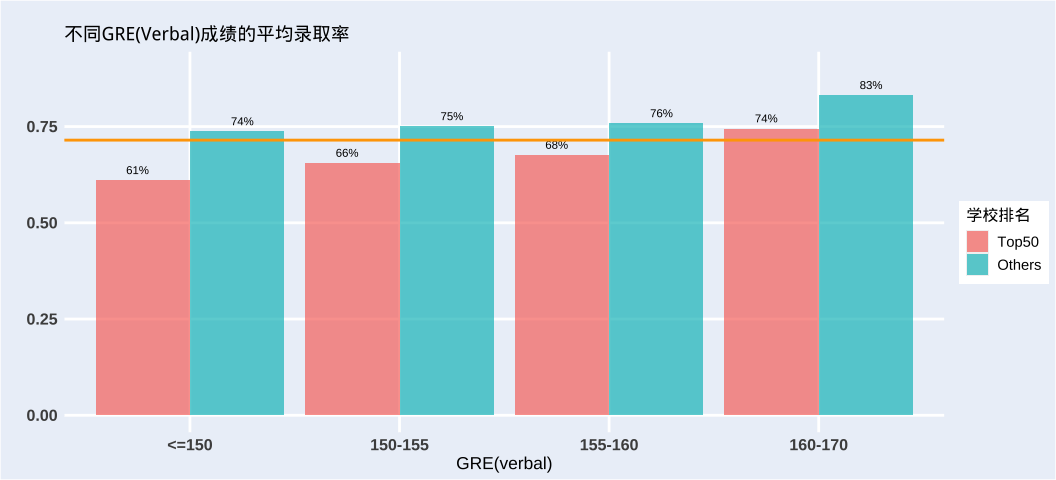
3. 英语成绩到底有多重要?
总有人说英语成绩只要差不多就行,但。。。GRE verbal 成绩对录取结果的影响表明,英语好还是非常重要的,英语太差申请Top50名校难度不小嗷。。。当然有可能是优秀的人各方面都不会差的,再次落泪。
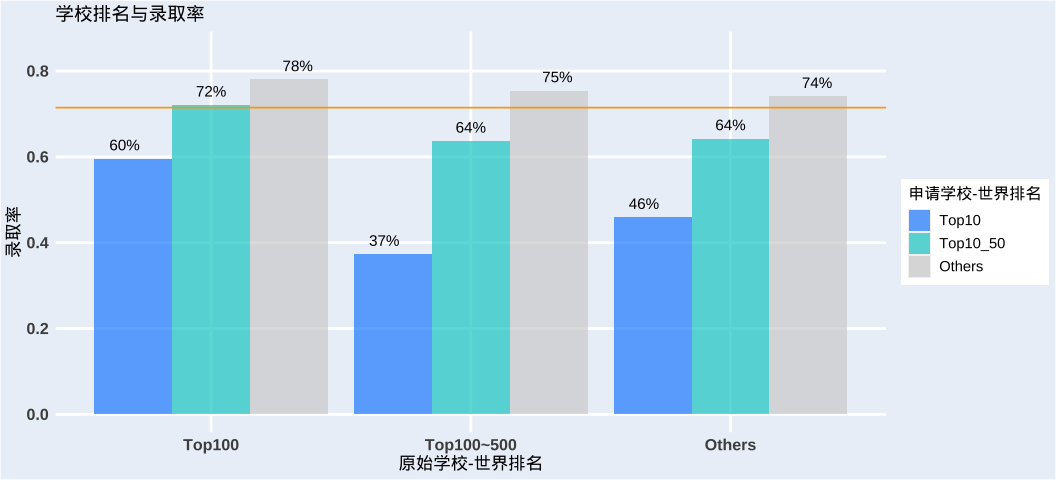
4.出身重要吗
of course!来自全球Top100的本科(清北复交港大等)就是很占优势。(我人呢,这次人大附中附属大学没有牌面,说好的全国Top3呢