第一部分:爬取弹幕
- b站搜索“s10”
https://search.bilibili.com/all?keyword=s10&from_source=nav_suggest_new&order=totalrank&duration=0&tids_1=4&page=1
改变page= 就可以翻页,从而爬取每个视频的title和网址
-
b站弹幕文件以 XML 文档式存储
-
对每一个视频:比如【总决赛抽签】:https://www.bilibili.com/video/BV1Ci4y1j7Gs
-
可以根据cid找到id——比如"cid":244696952
-
从而找到弹幕:
http://comment.bilibili.com/244696952.xml
-
-
爬取弹幕并提取
1.爬取关于s10的视频标题和链接
import requests #导入requests包
from lxml import etree # xpath
from bs4 import BeautifulSoup as BS
headers={'user-agent':'Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02'}
urls = []
titles = []
for num in range(1, 11):
url1 = "https://search.bilibili.com/all?keyword=s10&from_source=nav_suggest_new&order=totalrank&duration=0&tids_1=4&page="+str(num)
r = requests.get(url1, headers = headers) #获取数据
html = etree.HTML(r.text) # 处理为xpath可以操作的格式
li_tmp = html.xpath("//ul[@class='video-list clearfix']/li") # 得到所有li
for li in li_tmp:
urls.append(("http:"+li.xpath("./a/@href")[0])) # 提取视频网址
titles.append(li.xpath("./a/@title")[0]) # 提取标题
len(titles)
200
2.获取弹幕地址
import re
# 根据网址找到视频的弹幕地址
danmu = []
i = 0
for urli in urls:
i += 1
if i % 20==0: print(i)
r = requests.get(urli, headers = headers) #获取数据
pattern ='"cid":(\d+)'
cid = re.findall(pattern, r.text)
if cid == []:
danmu.append(None)
else:
danmu.append("http://comment.bilibili.com/" + str(cid[0]) + ".xml")
20
40
60
80
100
120
140
160
180
200
# 查看概况
import pandas as pd
data_raw = pd.DataFrame({'视频标题':titles, '网址':urls,'弹幕地址':danmu})
data_raw.head()
| 视频标题 | 网址 | 弹幕地址 | |
|---|---|---|---|
| 0 | 《S10四分之一女装决赛》 | http://www.bilibili.com/video/BV1cf4y1z73L?fro... | http://comment.bilibili.com/249115320.xml |
| 1 | S10采访有多难?余霜说前期准备都得双语份!【魔都电竞人】EP17 | http://www.bilibili.com/video/BV1Nr4y1w74z?fro... | http://comment.bilibili.com/248319821.xml |
| 2 | 【S10】2020LOL全球总决赛BGM 歌单合集(收录中) | http://www.bilibili.com/video/BV1bf4y1D7ea?fro... | http://comment.bilibili.com/240498380.xml |
| 3 | S10半决赛SN:TES 二路解说 (米勒娃娃) | http://www.bilibili.com/video/BV1XZ4y1G754?fro... | http://comment.bilibili.com/249474964.xml |
| 4 | 【英雄联盟】S10主题曲《所向无前》MV时间线重剪版 | http://www.bilibili.com/video/BV1ci4y1E7sx?fro... | http://comment.bilibili.com/237519965.xml |
import os
os.chdir("/Users/mac/Desktop/快乐研一/python/data/s10视频弹幕")
data_raw.to_csv("data_raw.csv", index_label = "index_label")
3.爬取弹幕内容
from bs4 import BeautifulSoup as BS
r = requests.get(danmu[0], headers = headers)
r.encoding = 'utf-8'
soup = BS(r.text,'lxml')
all_d = soup.find_all('d')
all_d[:10]
[<d p="79.48700,4,25,16777215,1603804760,0,9a617a42,40193273772900355">怎么感觉在憋笑</d>,
<d p="54.45200,1,25,16777215,1603804757,0,e4f81dba,40193271883890693">欧成也太行啦</d>,
<d p="14.95900,1,25,16777215,1603804266,0,e23a3f97,40193014642507781">???。</d>,
<d p="40.74000,1,25,16777215,1603803807,0,2b973602,40192773830737927">哈哈哈</d>,
<d p="27.46000,1,25,16777215,1603803789,0,2b973602,40192764451225603">爱了爱了</d>,
<d p="14.70000,1,25,16777215,1603803768,0,2b973602,40192753333698565">冲冲冲</d>,
<d p="8.54000,1,25,16777215,1603802300,0,2c556204,40191984122986501">咖哥太美了吧</d>,
<d p="9.85900,1,25,16777215,1603802164,0,2c556204,40191912440758275">咖哥绝没</d>,
<d p="64.51200,1,25,16777215,1603802021,0,20a366fa,40191837825138693">裂开</d>,
<d p="45.40700,1,25,16777215,1603802002,0,20a366fa,40191827817005063">草</d>]
## 写入文件夹
count = 1
for url_danmu in danmu:
r = requests.get(url_danmu, headers = headers)
r.encoding = 'utf-8'
soup = BS(r.text, 'lxml')
all_d = soup.find_all('d')
with open('{}.txt'.format(count), 'w', encoding='utf-8') as f:
for d in all_d:
f.write(d.get_text()+'\n')
if count%30 == 1:
print('第{}个视频弹幕写入完毕'.format(count))
count += 1
第1个视频弹幕写入完毕
第31个视频弹幕写入完毕
第61个视频弹幕写入完毕
第91个视频弹幕写入完毕
第121个视频弹幕写入完毕
第151个视频弹幕写入完毕
第181个视频弹幕写入完毕
第二部分 描述分析
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
jieba 分词
粗略学了一遍数据结构似乎理解这句话了:
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
import jieba
import os
import pandas as pd
os.chdir("/Users/mac/Desktop/快乐研一/python/data/s10视频弹幕")
jieba.load_userdict('人物.txt')
分词
# 对所有文章的弹幕进行分词合并
words = []
punctuation = '!!,;:??"\'、,;\n…。 #$&()\+\-\%\*\./¥'
# 1.对于所有的200个视频:
for n in range(1,201): # 对于所有的200个视频:
lines_n = open(str(n)+".txt","r",encoding = "utf-8").readlines() # 读入
# 2. 对一个视频的所有弹幕:
for i in range(len(lines_n)):
# 删除标点符号
line = re.sub(r'[{}]+'.format(punctuation),'',lines_n[i])
# 结巴分词
poss = jieba.cut(line)
words += [j for j in poss]
len(words)
words[:20]
500919
['怎么',
'感觉',
'在',
'憋',
'笑',
'欧成',
'也',
'太行',
'啦',
'哈哈哈',
'爱',
'了',
'爱',
'了',
'冲冲',
'冲',
'咖哥',
'太美',
'了',
'吧']
绘制词云图
#导入WordCloud和matplotlib包
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 在jupyter 里显示图片
import numpy as np
%matplotlib inline
# 生成一个matplot对象,传入一个字体位置的路径和背景颜色即可
wordcloud = WordCloud(
font_path='/Users/mac/Library/Fonts/字体管家方萌简(非商业使用)v1.1.ttf',
background_color='white',
width=1800,
height=1500,
)
人名出现次数
roles = [ i.replace('\n','').split("|") for i in open('人物.txt','r',encoding='utf-8').readlines()]
d_role = dict()
for role in roles:
times = 0
for name in role:
if name in words:
times += words.count(name)
d_role[role[0]] = times
#d_role
pd.DataFrame({"人名":list(d_role.keys()), "次数":list(d_role.values())}).sort_values(by='次数', ascending=False).head()
| 人名 | 次数 | |
|---|---|---|
| 9 | Jackeylove | 851 |
| 10 | 369 | 614 |
| 12 | Knight | 547 |
| 11 | Karsa | 515 |
| 7 | Caps | 377 |
fig = plt.figure(figsize=(9,9)) # 创建画布
wordcloud.fit_words(d_role)
plt.imshow(wordcloud)

队伍出现次数
teams = [ i.replace('\n','').split("|") for i in open('队伍.txt','r',encoding='utf-8').readlines()]
d_team = dict()
for team in teams:
times = 0
for name in team:
if name in words:
times += words.count(name)
d_team[team[0]] = times
#d_team
pd.DataFrame({"队伍":list(d_team.keys()), "次数":list(d_team.values())}).sort_values(by='次数', ascending=False).head()
| 队伍 | 次数 | |
|---|---|---|
| 1 | IG | 1931 |
| 2 | G2 | 1872 |
| 3 | TES | 1638 |
| 5 | SN | 1206 |
| 8 | DRX | 803 |
fig = plt.figure(figsize=(9,9)) # 创建画布
wordcloud.fit_words(d_team)
plt.imshow(wordcloud)
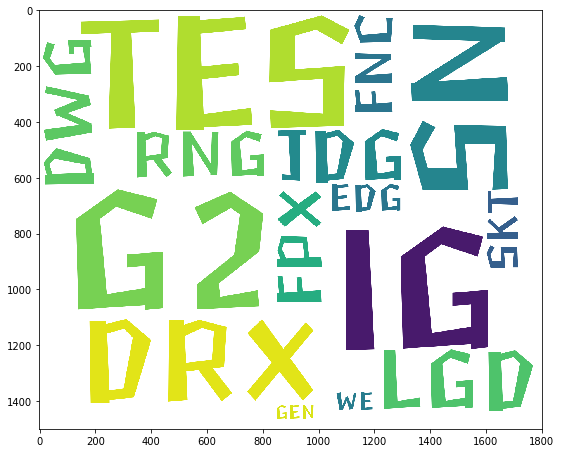
情感分析
snownlp 这个模块可以对每个单词得出情感得分。
训练数据主要是买卖东西时的评价,所以效果不好,暂且用它思考使用方法
有点慢,就随便挑了几期视频
1. 计算每一句弹幕的情感分数:
from snownlp import SnowNLP
scores = []
sentences = []
punctuation = '!!,;:??"\'、,;\n…。 #$&()\+\-\%\*\./¥'
# 1.对于所有的200个视频:
for n in range(100,130): # 对于所有的200个视频:
lines_n = open(str(n)+".txt","r",encoding = "utf-8").readlines() # 读入
# 2. 对一个视频的所有弹幕:
for i in range(len(lines_n)):
line = re.sub(r'[{}]+'.format(punctuation),'',lines_n[i])
if len(list(line))==0:
scores.append(None)
else:
scores.append(SnowNLP(line).sentiments)
sentences.append(line)
if n%5 == 1:
print("处理完第{}个视频".format(n))
处理完第101个视频
处理完第106个视频
处理完第111个视频
处理完第116个视频
处理完第121个视频
处理完第126个视频
Sentiment_df = pd.DataFrame({"句子":sentences,"情感":scores})
Sentiment_df.iloc[6040:6060,:]
Sentiment_df.shape
| 句子 | 情感 | |
|---|---|---|
| 6040 | 牙膏这里是不是想跟鳄鱼一块包夹的 | 0.649372 |
| 6041 | 仔细看首富卡视野和烬的平a细啊 | 0.971794 |
| 6042 | 富富富 | 0.553155 |
| 6043 | 熬到8点 | 0.300529 |
| 6044 | 有g2内鬼 | 0.522977 |
| 6045 | 这波huanfeng真的顶太吓人了 | 0.306918 |
| 6048 | sofm太猛了 | 0.729795 |
| 6049 | 京东plus会员还续费吗 | 0.389347 |
| 6050 | 年轻人不讲武德啊 | 0.915804 |
| 6051 | 这波硬头皮打大龙就3:0了 | 0.831243 |
| 6052 | 男枪一套秒了女枪 | 0.748254 |
| 6053 | g2下半区打韩国抗韩奇兵亮一下咋了 | 0.093364 |
| 6054 | 必须比莎比亚好 | 0.631785 |
| 6055 | 焕峰的烬太强了 | 0.822812 |
| 6056 | zoom拦个女的直接开始折磨 | 0.235975 |
| 6057 | 公爵难受啊 | 0.415783 |
(9052, 2)
2. 统计每一句弹幕是否包含队伍名称:
include_g2 = []
include_tes = []
include_sn = []
include_dwg = []
for sentence in sentences:
tmp = False
for team in teams[2]:
if team in sentence:
tmp = True
include_g2.append(tmp)
tmp = False
for team in teams[3]:
if team in sentence:
tmp = True
include_tes.append(tmp)
tmp = False
for team in teams[5]:
if team in sentence:
tmp = True
include_sn.append(tmp)
tmp = False
for team in teams[7]:
if team in sentence:
tmp = True
include_dwg.append(tmp)
Sentiment_df['G2'] = include_g2
Sentiment_df['TES'] = include_tes
Sentiment_df['SN'] = include_sn
Sentiment_df['DWG'] = include_dwg
Sentiment_df.iloc[100:110,:]
| 句子 | 情感 | G2 | TES | SN | DWG | |
|---|---|---|---|---|---|---|
| 100 | 胖了 | 0.384615 | False | False | False | False |
| 101 | 哈哈哈哈哈哈 | 0.975135 | False | False | False | False |
| 102 | 呸 | 0.526233 | False | False | False | False |
| 103 | TES输了 | 0.807744 | False | True | False | False |
| 104 | 胖了 | 0.384615 | False | False | False | False |
| 105 | 胖的跟个鬼一样 | 0.198050 | False | False | False | False |
| 106 | 之前都是异地登录打野账号 | 0.894432 | False | False | False | False |
| 107 | 三语翻译厉害呀 | 0.471007 | False | False | False | False |
| 108 | 送走了哈哈哈 | 0.885148 | False | False | False | False |
| 109 | 人机赛打架可以看看DWG打G2第4局 | 0.892714 | True | False | False | True |
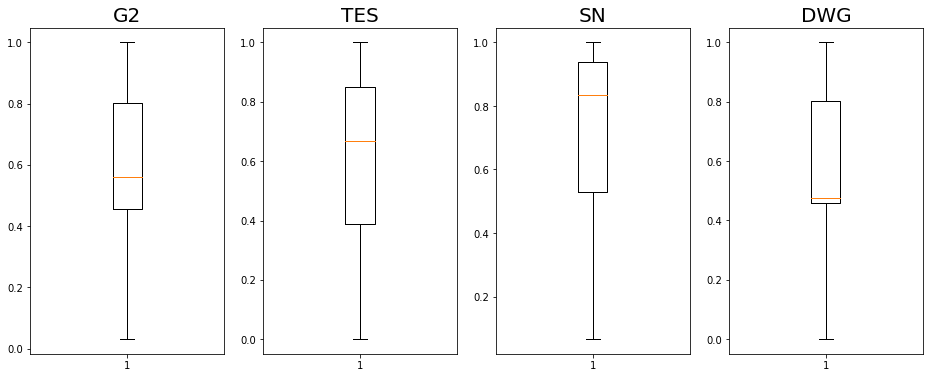
3. 绘制箱线图对比四支队伍的情感得分
team_sentiment = dict()
team_sentiment['G2'] = Sentiment_df[Sentiment_df['G2']]['情感']
team_sentiment['TES'] = Sentiment_df[Sentiment_df['TES']]['情感']
team_sentiment['SN'] = Sentiment_df[Sentiment_df['SN']]['情感']
team_sentiment['DWG'] = Sentiment_df[Sentiment_df['DWG']]['情感']
pd.DataFrame(team_sentiment).describe()
| G2 | TES | SN | DWG | |
|---|---|---|---|---|
| count | 258.000000 | 75.000000 | 151.000000 | 116.000000 |
| mean | 0.586540 | 0.617380 | 0.723949 | 0.573803 |
| std | 0.254834 | 0.281933 | 0.269218 | 0.249054 |
| min | 0.031252 | 0.001094 | 0.066510 | 0.000180 |
| 25% | 0.457284 | 0.387117 | 0.528126 | 0.457027 |
| 50% | 0.561343 | 0.669569 | 0.835424 | 0.475006 |
| 75% | 0.802808 | 0.849809 | 0.938778 | 0.802086 |
| max | 0.999967 | 0.999884 | 0.999836 | 0.999823 |