使用 requests 抓取+bs4结构化
import numpy as np
import pandas as pd
import requests #导入requests包
from bs4 import BeautifulSoup
## 将代码块运行结果全部输出,而不是只输出最后的,适用于全文
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import warnings
warnings.filterwarnings('ignore')
url = 'http://www.cntour.cn/'
strhtml = requests.get(url) #Get方式获取网页数据,是一个 URL 对象,它代表整个网页
soup = BeautifulSoup(strhtml.text,"html.parser")
#print(soup) # 把爬取的内容结构化了
soup.title
soup.find_all('a')[:5]
print(soup.get_text()[:10])
中国旅游网
简单实例1——爬取中国大学排名
https://www.shanghairanking.cn/rankings/bcur/2020
import requests
from bs4 import BeautifulSoup
allUniv = []
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
url = 'https://www.shanghairanking.cn/rankings/bcur/2020.html'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
schools = soup.find_all('tr')
# 选择清华大学进行尝试
school1 = schools[2]
print("\n1.以清华大学为例:\n")
print(school1)
# 把清华各类信息分割开,根据<td>
school1_str = school1.find_all("td")
tsinghua = []
# 提取文字部分
for i in range(len(school1_str)):
tsinghua.append(school1_str[i].get_text("|", strip=True)) # 删掉空白
print("\n2.提取文字部分:\n")
print(tsinghua)
1.以清华大学为例:
<tr data-v-45ac69d8=""><td data-v-45ac69d8="">
1
</td><td class="align-left" data-v-45ac69d8=""><a data-v-45ac69d8="" href="/institution/tsinghua-university">清华大学</a> <p data-v-45ac69d8="" style="display:none"></p></td><td data-v-45ac69d8="">
北京
</td><td data-v-45ac69d8="">
综合
</td><td data-v-45ac69d8="">
852.5
</td><td data-v-45ac69d8="">
38.2
</td></tr>
2.提取文字部分:
['1', '清华大学', '北京', '综合', '852.5', '38.2']
import pandas as pd
# 用dataframe存储爬取结果
univ_rank = []
for i in range(2,len(schools)):
school = schools[i]
school_str = school.find_all("td")
datalist = []
# 提取文字部分
for j in range(len(school_str)):
datalist.append(school_str[j].get_text("|", strip=True)) # 删掉空白
univ_rank.append(datalist)
univ_rank_df = pd.DataFrame(univ_rank, columns= ["排名","学校名称","省市","类型","总分","办学层次"])
univ_rank_df.head()
univ_rank_df.shape
| 排名 | 学校名称 | 省市 | 类型 | 总分 | 办学层次 | |
|---|---|---|---|---|---|---|
| 0 | 1 | 清华大学 | 北京 | 综合 | 852.5 | 38.2 |
| 1 | 2 | 北京大学 | 北京 | 综合 | 746.7 | 36.1 |
| 2 | 3 | 浙江大学 | 浙江 | 综合 | 649.2 | 33.9 |
| 3 | 4 | 上海交通大学 | 上海 | 综合 | 625.9 | 35.4 |
| 4 | 5 | 南京大学 | 江苏 | 综合 | 566.1 | 35.1 |
(567, 6)
简单实例2——学院官网会议信息
url = 'http://www.math.sjtu.edu.cn/research/seminar.php'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
# <a href="seminar-show.php?id=4068">
soup.find_all("a",href="seminar-show.php?id=4068")
def has_class_but_no_id(tag):
return tag.has_attr('href') and not tag.has_attr('class')
xx = soup.find_all(has_class_but_no_id)
xx[0].find("a")
[<a href="seminar-show.php?id=4068">
<div class="title">
<div class="zh">
<span style="color: #F4A011;">
[COLLOQUIUM] </span>
杨伟豪 </div>
<div class="en">TBA</div>
</div>
<div class="time">
<div class="date">2020-11-27</div>
<div class="hour">14:00 — 15:15</div>
</div>
</a>]
import re # 正则表达式,选出href包含这一串字符的标签
def ifseminar(href):
return href and re.compile("seminar\-show.php\?id=+\d{4}").search(href) # 正则表达式匹配
xx = soup.find_all(href = ifseminar)
# 取一场会议的看看
xx[0]
#xx[0].get_text(",", strip=True).split(",")
#xx[1].get_text(",", strip=True).split(",")
# 注意有些会议有分类,因此如果len=4,要在会议分类一项设为None
Seminars = []
for i in range(0,len(xx)):
tmp = xx[i].get_text("|", strip=True).split("|")
if len(tmp)==4:
tmp.insert(0, None)
Seminars.append(tmp)
seminars_df = pd.DataFrame(Seminars, columns= ["类型","报告人","标题","日期","时间"])
seminars_df.iloc[:10,:]
<a href="seminar-show.php?id=4068">
<div class="title">
<div class="zh">
<span style="color: #F4A011;">
[COLLOQUIUM] </span>
杨伟豪 </div>
<div class="en">TBA</div>
</div>
<div class="time">
<div class="date">2020-11-27</div>
<div class="hour">14:00 — 15:15</div>
</div>
</a>
| 类型 | 报告人 | 标题 | 日期 | 时间 | |
|---|---|---|---|---|---|
| 0 | [COLLOQUIUM] | 杨伟豪 | TBA | 2020-11-27 | 14:00 — 15:15 |
| 1 | None | 刘会 教授 | The multiplicity and stability conjectures abo... | 2020-11-19 | 10:00 — 11:30 |
| 2 | [INS COLLOQUIUM] | Alberto Bressan | Distinguished Lecture in Celebration of the 10... | 2020-11-10 | 10:00 — 11:00 |
| 3 | None | 骆威 | On order determination by predictor augmentation | 2020-11-05 | 14:00 — 15:00 |
| 4 | None | 杜增吉 | Dynamics of traveling waves for shallow water ... | 2020-10-29 | 14:00 — 15:00 |
| 5 | None | 陈和柏 | 连续分段线性系统的奇点分类及其相应奇点指标 | 2020-10-29 | 15:00 — 16:30 |
| 6 | None | 张荣茂 | Identifying Cointegration under High-dimension... | 2020-10-28 | 14:00 — 15:00 |
| 7 | [INS COLLOQUIUM] | Chi-wang Shu | Distinguished Lecture in Celebration of the 10... | 2020-10-27 | 09:30 — 10:30 |
| 8 | None | 朱文圣 | Concordance Matched Learning for Estimating Op... | 2020-10-27 | 14:00 — 15:00 |
| 9 | None | 李骥 | Orbital stability of the Degasperis-Procesi eq... | 2020-10-23 | 15:00 — 16:00 |
简单实例3——如何爬取下一页
爬取下厨房网站的早餐(下一页有明显规律)
http://www.xiachufang.com/category/40071/
网页源代码通常从前几行可以看到声明,例如 content = 'text/html; charset = 'gbk'
字符编码是gbk
headers={"user-agent:xxx"}模拟浏览器——反爬虫
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
recipes = []
for i in range(1,12): # 爬取10页内容
urli = "http://www.xiachufang.com/category/40071/?page="+str(i) # 循环爬取下一页
res = requests.get(urli, headers = headers) #获取数据
html = res.text
soup = BeautifulSoup(html,'html.parser')
recipei = soup.find_all("div", class_ = "info pure-u")
recipes += recipei # 合并到一起
len(recipes)
236
# 提取变量
recipeslist = []
for i in range(len(recipes)):
recipe0 = recipes[i]
tmp = [""]*5
tmp[0] = recipe0.a.get_text(strip = True) # 标题
tmp[1] = recipe0.find("p", class_ = "ing ellipsis").get_text(strip = True).split("、") # 食材
if recipe0.find("span", class_ = "score bold green-font") == None: # 评分
tmp[2] = None
else:
tmp[2] = np.float(recipe0.find("span", class_ = "score bold green-font").get_text())
if recipe0.find("span", class_ = "bold score") == None: # 做过人数
tmp[3] = None
else:
tmp[3] = np.int(recipe0.find("span", class_ = "bold score").get_text())
tmp[4] = recipe0.find("a", class_ = "gray-font").get_text() # 作者
recipeslist.append(tmp)
# 整理为dataframe
recipes_df = pd.DataFrame(recipeslist, columns= ["标题","食材","评分","做过的人数","作者"])
recipes_df.iloc[:13, ]
recipes_df.shape
| 标题 | 食材 | 评分 | 做过的人数 | 作者 | |
|---|---|---|---|---|---|
| 0 | 四十八天不重样早餐 | [主食, 果蔬, 肉蛋] | 7.6 | 12.0 | cincintoitoitoi |
| 1 | 5分钟快手早餐——鸡蛋饼 | [鸡蛋, 面粉, 火腿肠, 辣酱, 芝麻酱, 孜然粉, 盐] | 7.7 | 2.0 | 吃吃喝喝小主妇 |
| 2 | 面片汤 | [馄饨皮, 西红柿, 鸡蛋, 水, 菠菜, 葱花, 酱油, 十三香, 盐, 味精或是鸡精, 糖] | 8.3 | 5.0 | wupeilu115 |
| 3 | 秒杀路边摊的鸡蛋汉堡 | [面粉, 水, 鸡蛋, 火腿肠, 香葱, 剩的饺子馅, 盐, 泡打粉, 孜然粉, 花椒粉, ... | 8.1 | 1.0 | H_美食爱好者 |
| 4 | 解决孩子不吃菜难题的胡萝卜蔬菜厚蛋烧鸡蛋卷 | [鸡蛋, 水果胡萝卜, 盐, 双汇火腿, 韭菜, 生抽, 白糖] | 8.1 | 1.0 | 殇婆子 |
| 5 | 家有小学生,每周早餐不重样(10.12-10.18) | [爱] | NaN | 0.0 | 大元子的元 |
| 6 | 吐司这样吃-一周减脂三明治不重样 | [吐司片, 鸡蛋, 生菜, 芝士片, 胡萝卜, 火腿片, 鸡胸肉, 金枪鱼罐头, 虾仁, 颗... | 8.2 | 7.0 | 姚小胖MissYiu |
| 7 | 一碗清汤面 🍜 —— 秋日里的治愈系 | [拉面, 香葱, 小米椒, 蒜蓉, 生抽, 陈醋, 盐, 鸡精, 黑胡椒] | 8.3 | 54.0 | Ane_思远哥哥 |
| 8 | 玉米面松饼,早起5分钟搞定,又软又健康 | [玉米面, 白面, 鸡蛋, 白糖, 酵母粉, 温水] | 8.1 | 8.0 | 豆妈糕点1 |
| 9 | 家庭版土豆丝卷饼 | [土豆, 胡萝卜, 青椒丝, 葱花, 牛肉粉, 蚝油, 花椒粉, 生抽, 盐, 面粉, 盐,... | 8.4 | 2.0 | 风飘千雪496631161 |
| 10 | 我的破壁养生路(分享破壁机食谱,不断更新中) | [各种五谷杂粮, 各种蔬菜水果] | 8.7 | 2.0 | 马宝宝的妈咪 |
| 11 | 连着3天儿子都点名要吃的晚餐,剪刀面 | [鸡蛋, 西红柿, 火腿肠, 面粉, 菠菜] | 8.0 | 12.0 | 豆妈糕点1 |
| 12 | 和风海苔虾滑蛋三明治【健康一手握】 | [吐司或欧包汉堡胚随便你, 第戎芥末籽酱, 寿司海苔, 芝士, 虾仁, 盐, 黑胡椒, 鸡蛋... | 9.5 | 2.0 | 一只有猫病的Sunsun |
(236, 5)
## 统计各个食材用于早餐的次数
shicai = recipes_df['食材']
d = {}
type_num = []
for i in range(len(shicai)):
type_num.append(len(shicai[i]))
for j in range(len(shicai[i])):
tmp = shicai[i][j]
if tmp not in d:
d[tmp] = 1
else:
d[tmp] += 1
# 最常出现的食材
hot_shicai = sorted(d.items(), key = lambda item:item[1],reverse=True)[:8]
hot_shicai = [[i[0],i[1]] for i in hot_shicai]
hot_shicai = pd.DataFrame(hot_shicai, columns= ['食材名称','出现次数'])
hot_shicai
# 每个早餐需要的食材数目
np.mean(type_num)
| 食材名称 | 出现次数 | |
|---|---|---|
| 0 | 盐 | 103 |
| 1 | 鸡蛋 | 83 |
| 2 | 面粉 | 51 |
| 3 | 水 | 41 |
| 4 | 牛奶 | 39 |
| 5 | 酵母 | 37 |
| 6 | 糖 | 30 |
| 7 | 生抽 | 27 |
7.190677966101695
试着对以上数据做些描述
# matplotlib 中的pyplot函数,用于画图
import matplotlib.pyplot as plt # 命名为plt
# 在jupyter 里显示图片
import numpy as np
%matplotlib inline
# font_manager函数,用于指定中文字体样式、大小
import matplotlib.font_manager as mfm
# 设置字体
font_path = r"/Users/mac/Library/Fonts/字体管家方萌简(非商业使用)v1.1.ttf"
prop = mfm.FontProperties(fname = font_path)
# 画图主题
plt.style.use('seaborn-white') # 指定全局画图主题为ggplot
#plt.style.use('ggplot')
fig = plt.figure(figsize=(18,12)) # 画布
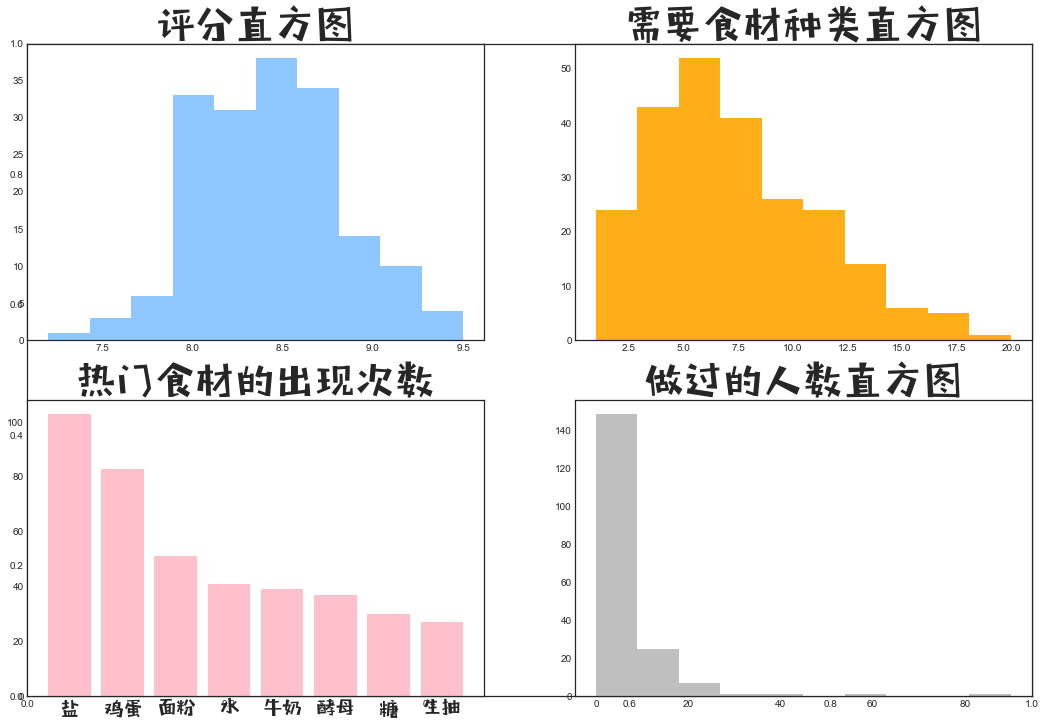
# 1.评分的直方图
ax1 = fig.add_subplot(111) # 创建子图
ax1 = fig.add_subplot(2,2,1) # 创建2*2=4张图,ax1画在第一张图上
ax1.hist(x = recipes_df['评分'].dropna(axis=0), color = "dodgerblue",alpha = 0.5)
ax1.set_title('评分直方图', fontproperties=prop, fontsize=40) # 图标题
# 2.食材数目直方图
ax2 = fig.add_subplot(111) # 创建子图
ax2 = fig.add_subplot(2,2,2) # 创建2*2=4张图,ax1画在第一张图上
ax2.hist(x = type_num, color = "orange", alpha = 0.9)
ax2.set_title('需要食材种类直方图', fontproperties=prop, fontsize=40) # 图标题
# 3.热门食材的出现次数
ax3 = fig.add_subplot(111) # 创建子图
ax3 = fig.add_subplot(2,2,3) # 创建2*2=4张图,ax1画在第一张图上
ax3.bar(hot_shicai['食材名称'], hot_shicai['出现次数'], color = "pink")
ax3.set_title('热门食材的出现次数', fontproperties=prop, fontsize=40) # 图标题
ax3.set_xticklabels(labels =hot_shicai['食材名称'], fontproperties=prop, fontsize=20)
# 4.做过的人数直方图
ax4 = fig.add_subplot(111) # 创建子图
ax4 = fig.add_subplot(2,2,4) # 创建2*2=4张图,ax1画在第一张图上
ax4.hist(x = recipes_df['做过的人数'].dropna(axis=0), color = "grey",alpha = 0.5)
ax4.set_title('做过的人数直方图', fontproperties=prop, fontsize=40) # 图标题
plt.show() # 画图
plt.close() # plt.show()结束后仍然保存在内存中, 切记关闭!!!在jupyter理!!!